

개요
때는... 2023년 5월 24일. MeetCoder 10기 첫번째 밑업을 진행하던 중이었다.
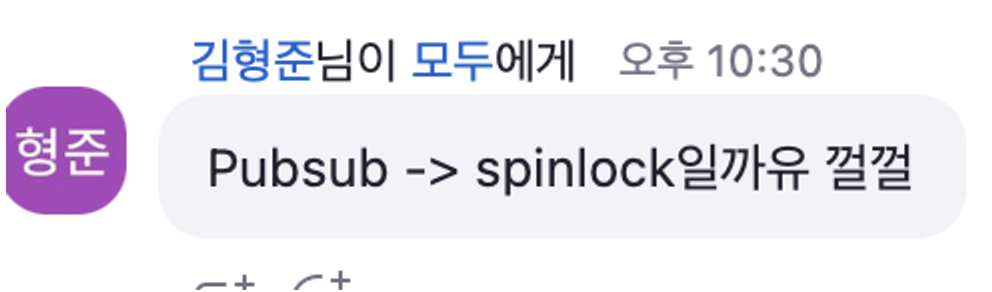
민철님의 '분산락을 이용한 동시성 이슈 해결' 발표가 진행되던 중 채팅창에 요런 질문이 나왔다. 스핀락...? 스핀락이 뭐지? 🤔 태어나서 처음 들어본 (또는 들었는데 까먹은) spin lock에 대해 낱낱이 파헤쳐보려 한다 😎
Spinlock (스핀락)의 정의
Race Condition 상황에서 Lock이 반환될 때까지, 즉 Critical section에 진입 가능할 때까지 프로세스가 재시도하며 대기하는 상태
본격적인 설명에 앞서 스핀락의 정의는 위와 같다. 와! 한 문장에서 영어 단어가 3개나 나왔다! 하나씩 풀어서 살펴보자.
Race Condition (경쟁 상태)
멀티 프로세스 환경에서 프로세스가 수행되는 순서에 따라 결과 값이 달라질 수 있는 상황
멀티 스레드 환경에서 아래와 같은 상황이 발생한다고 가정하자.
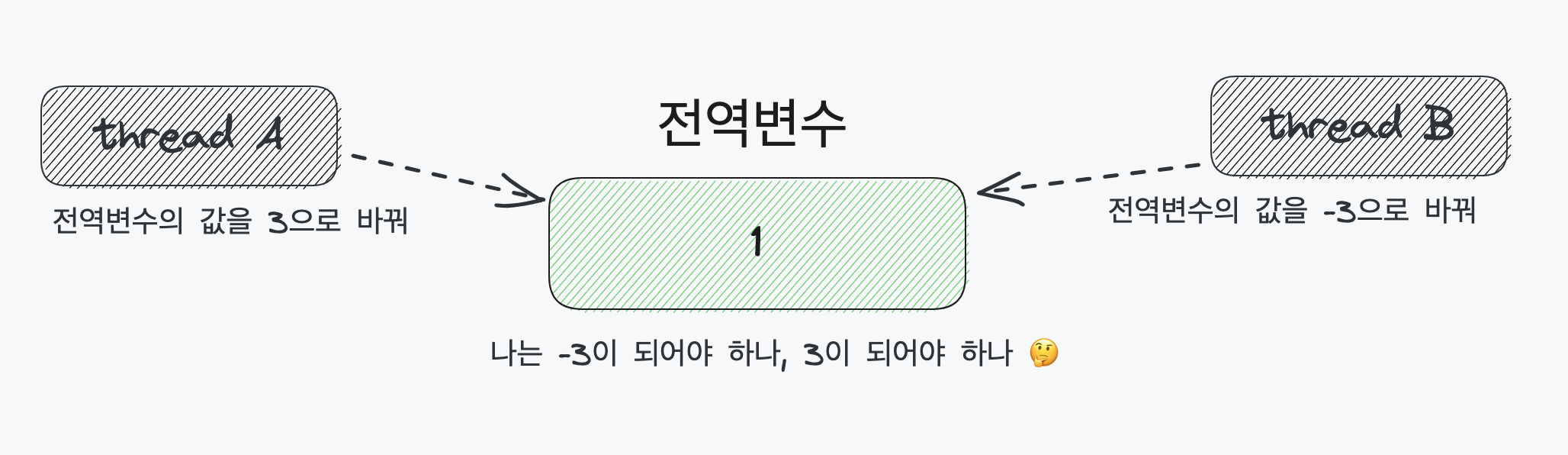
스레드 A와 B가 동시에 동일한 변수의 값을 바꾸려 한다면, 컴퓨터는 해당 변수의 값을 무엇으로 바꾸어야할 지 알 수 없다. 따라서 스레드 동작 순서에 따라 값을 결정하게 된다. 이런 상황에서 스레드 내부에서 이전 행동의 값을 바탕으로 다음 행동을 결정하는 요청이 있다고 가정하면, 더더욱 유저가 예기치 못한 문제가 발생할 가능성이 커진다.
운영체제에서는 이렇게 프로세스가 수행되는 순서에 따라 결과 값이 달라질 수 있는 상황을 Race Condition (경쟁 상태) 라고 부른다. DB를 공부하다 듣는 트랜잭션 동시성 제어를 생각해보자. 특정 레코드에 대한 동시 접근은 데이터의 정합성을 보장하지 못한다. 마찬가지로 공유 자원에 대한 동시 접근은 스레드가 cpu를 빼앗기는 타이밍에 데이터의 정합성이 깨지게 된다.
(DB에서의 트랜잭션을 OS에서의 프로세스라고 생각하면 될 것 같다 👀)
그리고 이런 경쟁 상태를 야기하는 상황을, 임계 구역에 동시에 여러 스레드가 접근한 상황이라고 정리할 수 있다.
Critical Section (임계 영역)
여러 스레드 또는 프로세스가 공유 자원에 접근할 수 있는 코드 영역.
즉, 코드 상에서 Race condition (경쟁 상태)가 발생할 수 있는 곳으로, 둘 이상의 스레드가 동시에 접근하면 안되는 구역.
아마 대강 감이 오실 것 같다. Java 코드로 예시를 들어보자.
public class Counter {
public int count;
public synchronized void increase() {
count++;
}
public synchronized void decrease() {
count--;
}
}(여기의 예시를 인용했습니다.)
위와 같은 코드에서 increase(), decrease() 메서드는 동일한 count 변수에 접근하는 임계 영역이다. 이전에 포스팅했던 count 구현 방법 중 4번째의 예시를 생각해보자. count가 레코드 값이고, 각 메서드가 트랜잭션이라고 생각하면 갱신 손실 문제가 발생할 것이 명백한 상황이다.
하지만 위 코드는 동기화 문제에서 비교적 자유롭다. synchronized 키워드를 사용했기 때문이다. 각 메서드에 걸린 synchronized 키워드를 이용해, 멀티 스레드 환경에서 특정 스레드가 먼저 임계 영역 안으로 들어오면 (= 메서드를 호출하면) 락을 걸어주는 (= 스레드를 순차적으로 실행하는) 구조이다. 이처럼 임계 영역에서 경쟁 상태를 방지하기 위해, 우리는 다양한 동기화 기법을 사용할 수 있다.
즉 경쟁 상태를 방지하고 데이터의 일관성을 유지하기 위해 동기화 과정이 필요한데, 여기서 사용되는 것이 Lock 이다.
Lock (락 / 잠금)
공유 자원을 특정 스레드가 사용하고 있을 때, 다른 스레드는 해당 공유 자원에 접근할 수 없도록 제한하는 것
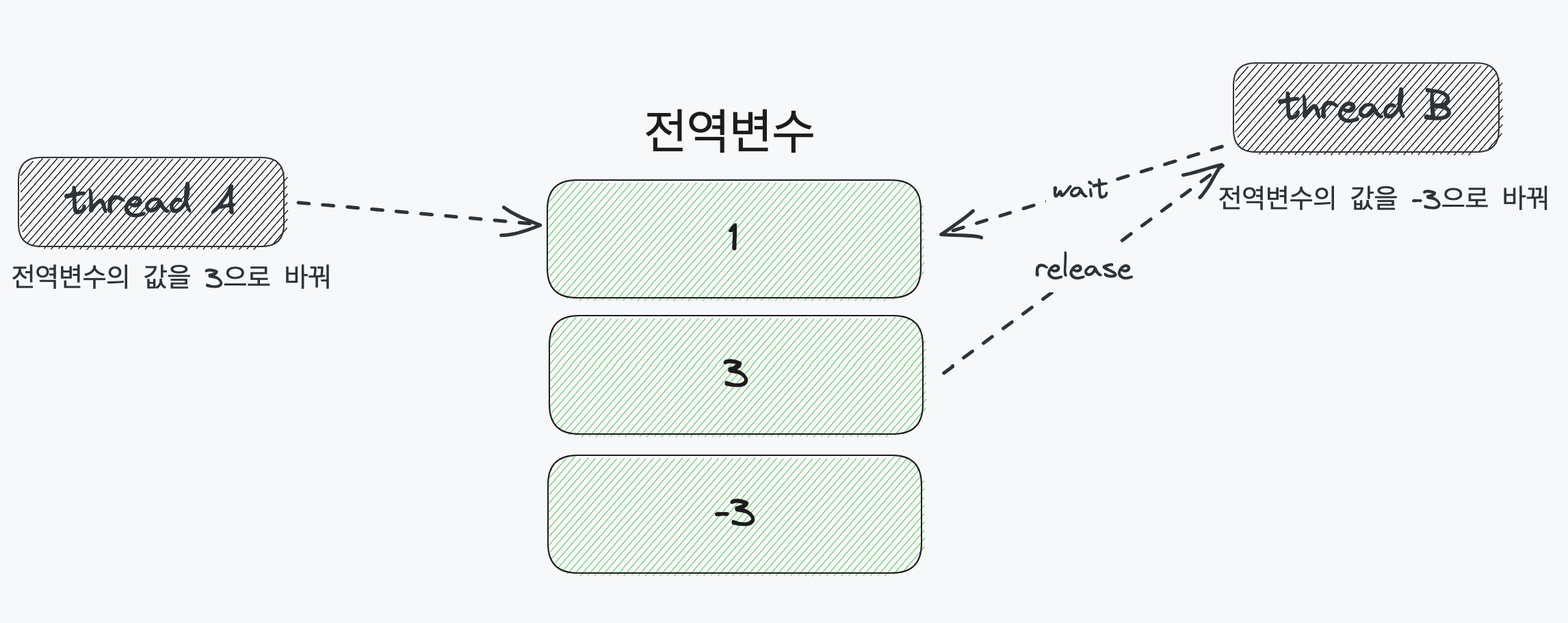
위 그림을 다시 보자. 스레드 A가 접근하면 공유 자원에 락을 걸어 스레드 B가 접근하지 못하게 만든다. 스레드 A의 작업이 종료되면 락을 풀고 ( = release = unlock) 대기(wait) 중이던 스레드 B가 작업을 수행하게 만든다.
이렇게 스레드를 순차적으로 실행하게 만들면 공유 자원의 동기화를 구현할 수 있다. 여기에 사용되는 Lock의 종류 중 하나가 바로 오늘의 주제인 Spinlock 이다.
Spinlock (스핀락)
스레드가 락을 얻을 때까지 무한 루프를 돌며 확인하는 동기화 매커니즘
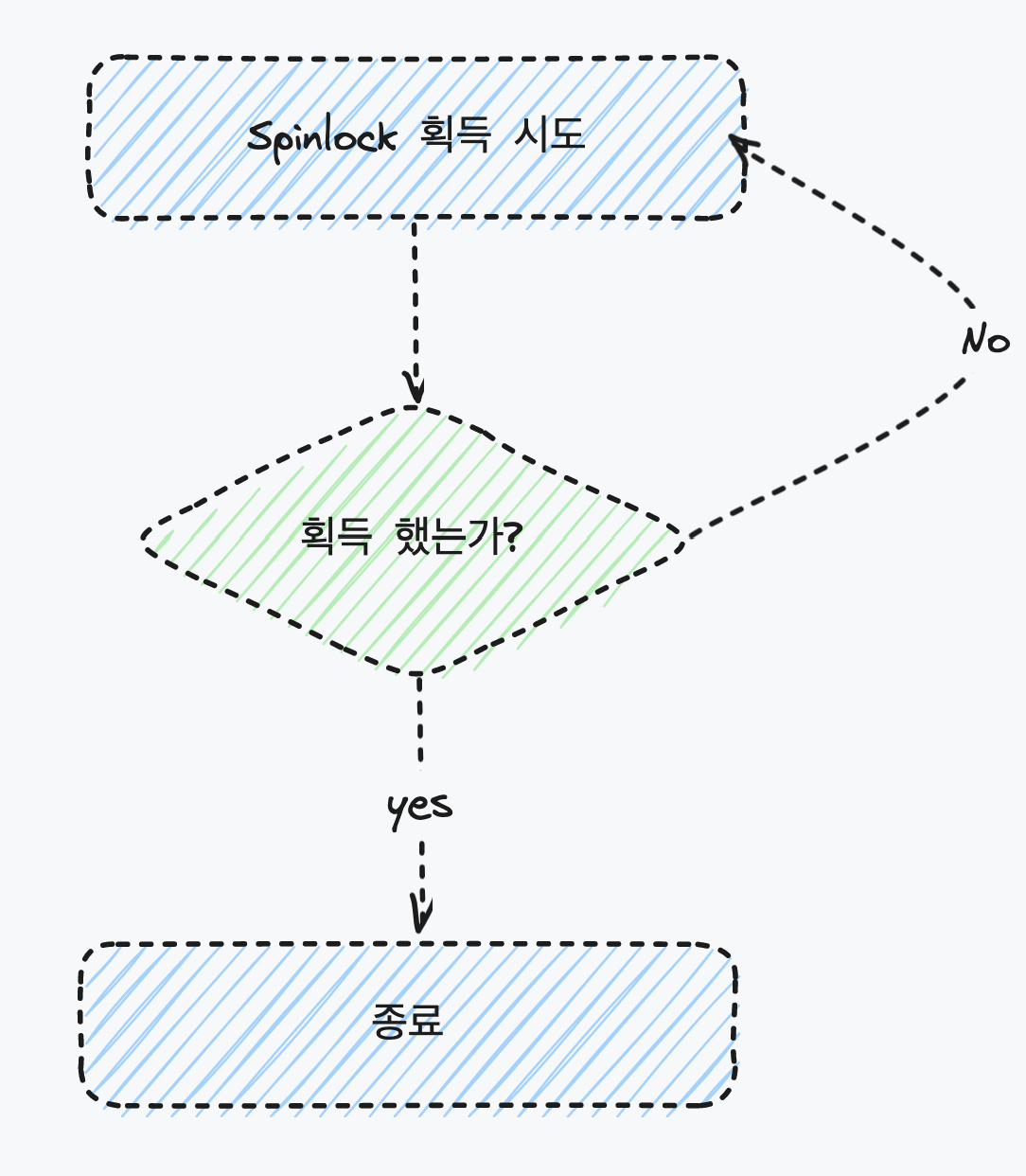
위에서 설명한 동기화 매커니즘의 원리를 다시 풀어보자. 먼저 스레드가 실행되는 동안 (= CPU를 점유하는 동안) 공유 자원에 락을 걸고, 스레드의 작업이 종료되면 락을 해제한다. 따라서 다음 스레드가 CPU를 차지하기 위해선 공유 자원에 락이 걸렸는지 걸리지 않았는지를 파악하는 과정이 필요하다.
스핀락은 대기 중인 스레드가 공유 자원의 상태를 무한 루프를 이용해 확인하는 방식이다. 락이 걸려있으면 작업하지 못하고, 락이 걸려있지 않다면 작업할 수 있으니 그냥 무작정 반복적으로 Lock이 반환될 때까지 확인하며 대기하는 것이다.
이러한 스핀락은 OS의 스케줄링 지원을 받지 않기에, 해당 스레드에 대한 context switching (문맥 교환)이 일어나지 않는다는 특징이 있다.
Context switching
: 하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하기 위해 이전 프로세스의 문맥을 보관하고 새로운 프로세스의 상태를 적재하는 작업
스핀락의 장단점
😎 장점
위에서 스핀락은 스레드가 대기 상태로 전환되지 않기에 문맥 교환이 일어나지 않는 특징을 갖는다고 언급했다. 따라서 다음의 장점을 갖는다.
- 문맥 교환에 필요한 CPU의 오버헤드를 줄일 수 있다 (문맥 교환 중엔 어떤 작업을 수행할 수 없음)
- 락의 획득이 빠르다 (무한 루프 속에서 반복해서 락을 확인하기 때문)
🤥 단점
스핀락의 정의를 보자. 락을 획득할 때까지 무한 루프를 도는 친구다. 이 작업 자체가 CPU를 많이 잡아먹는다는 단점이 있다. 임계 영역이 한 두개가 아니라 여러 개라면? 또 락이 반환될 때까지 오랜 시간이 걸린다면? 따라서 다음의 단점을 갖는다.
- Busy waiting : 스핀락의 획득을 위해 CPU의 오버헤드가 발생할 수 있다. (무한루프를 돌면서 CPU를 계속 사용함)
- Starvation (기아 상태) : 특정 스레드나 프로세스가 공유 자원을 오랫동안 점유한다면, 다른 스레드들이 대기 상태에 갇힐 수 있다.
적용
💡 스핀락은 스레드나 프로세스의 경합 상황이 짧을 때 ( = 임계 구역에서의 작업이 빠르게 이루어질 때) 유용하다.
⚡️ 스핀락의 무한 루프 덕분에 락의 획득과 반환이 빨라 실행 속도도 빨라지고, 문맥 교환이 생략되기에 CPU의 오버헤드도 줄어든다.
💡 스핀락은 여러 개의 CPU 코어가 존재할 때 유용하다.
⚡️ 사용하지 않는 CPU 코어에서 스핀락을 통해 대기하다가 바로 락을 획득할 수 있다. (사실 단일 코어일 땐 스핀락이 의미가 없기도 하고..!)
트레이드 오프를 고려하여, 경합 상황이 길거나 싱글 CPU일 경우엔 다른 동기화 메커니즘 (ex. 뮤텍스, 세마포어 등)을 고려해보자.
레퍼런스
문맥 교환 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. -->
ko.wikipedia.org
스핀락 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 스핀락(spinlock)은 임계 구역(critical section)에 진입이 불가능할 때 진입이 가능할 때까지 루프를 돌면서 재시도하는 방식으로 구현된 락을 가리킨다. 스핀락이라
ko.wikipedia.org
- 프로세스 동기화 : https://rebro.kr/176
[운영체제(OS)] 6. 프로세스 동기화(Process Synchronization)
[목차] 1. Race Condition 2. Critical Section 3. Synchronization Algorithms 4. Synchronization Hardware 5. Mutex Locks 6. Semaphores 7. Classical Problems of Synchronization 8. Monitor 참고) - https://parksb.github.io/article/10.html - KOCW 공개강의
rebro.kr
개요
때는... 2023년 5월 24일. MeetCoder 10기 첫번째 밑업을 진행하던 중이었다.
민철님의 '분산락을 이용한 동시성 이슈 해결' 발표가 진행되던 중 채팅창에 요런 질문이 나왔다. 스핀락...? 스핀락이 뭐지? 🤔 태어나서 처음 들어본 (또는 들었는데 까먹은) spin lock에 대해 낱낱이 파헤쳐보려 한다 😎
Spinlock (스핀락)의 정의
Race Condition 상황에서 Lock이 반환될 때까지, 즉 Critical section에 진입 가능할 때까지 프로세스가 재시도하며 대기하는 상태
본격적인 설명에 앞서 스핀락의 정의는 위와 같다. 와! 한 문장에서 영어 단어가 3개나 나왔다! 하나씩 풀어서 살펴보자.
Race Condition (경쟁 상태)
멀티 프로세스 환경에서 프로세스가 수행되는 순서에 따라 결과 값이 달라질 수 있는 상황
멀티 스레드 환경에서 아래와 같은 상황이 발생한다고 가정하자.
스레드 A와 B가 동시에 동일한 변수의 값을 바꾸려 한다면, 컴퓨터는 해당 변수의 값을 무엇으로 바꾸어야할 지 알 수 없다. 따라서 스레드 동작 순서에 따라 값을 결정하게 된다. 이런 상황에서 스레드 내부에서 이전 행동의 값을 바탕으로 다음 행동을 결정하는 요청이 있다고 가정하면, 더더욱 유저가 예기치 못한 문제가 발생할 가능성이 커진다.
운영체제에서는 이렇게 프로세스가 수행되는 순서에 따라 결과 값이 달라질 수 있는 상황을 Race Condition (경쟁 상태) 라고 부른다. DB를 공부하다 듣는 트랜잭션 동시성 제어를 생각해보자. 특정 레코드에 대한 동시 접근은 데이터의 정합성을 보장하지 못한다. 마찬가지로 공유 자원에 대한 동시 접근은 스레드가 cpu를 빼앗기는 타이밍에 데이터의 정합성이 깨지게 된다.
(DB에서의 트랜잭션을 OS에서의 프로세스라고 생각하면 될 것 같다 👀)
그리고 이런 경쟁 상태를 야기하는 상황을, 임계 구역에 동시에 여러 스레드가 접근한 상황이라고 정리할 수 있다.
Critical Section (임계 영역)
여러 스레드 또는 프로세스가 공유 자원에 접근할 수 있는 코드 영역.
즉, 코드 상에서 Race condition (경쟁 상태)가 발생할 수 있는 곳으로, 둘 이상의 스레드가 동시에 접근하면 안되는 구역.
아마 대강 감이 오실 것 같다. Java 코드로 예시를 들어보자.
public class Counter {
public int count;
public synchronized void increase() {
count++;
}
public synchronized void decrease() {
count--;
}
}(여기의 예시를 인용했습니다.)
위와 같은 코드에서 increase(), decrease() 메서드는 동일한 count 변수에 접근하는 임계 영역이다. 이전에 포스팅했던 count 구현 방법 중 4번째의 예시를 생각해보자. count가 레코드 값이고, 각 메서드가 트랜잭션이라고 생각하면 갱신 손실 문제가 발생할 것이 명백한 상황이다.
하지만 위 코드는 동기화 문제에서 비교적 자유롭다. synchronized 키워드를 사용했기 때문이다. 각 메서드에 걸린 synchronized 키워드를 이용해, 멀티 스레드 환경에서 특정 스레드가 먼저 임계 영역 안으로 들어오면 (= 메서드를 호출하면) 락을 걸어주는 (= 스레드를 순차적으로 실행하는) 구조이다. 이처럼 임계 영역에서 경쟁 상태를 방지하기 위해, 우리는 다양한 동기화 기법을 사용할 수 있다.
즉 경쟁 상태를 방지하고 데이터의 일관성을 유지하기 위해 동기화 과정이 필요한데, 여기서 사용되는 것이 Lock 이다.
Lock (락 / 잠금)
공유 자원을 특정 스레드가 사용하고 있을 때, 다른 스레드는 해당 공유 자원에 접근할 수 없도록 제한하는 것
위 그림을 다시 보자. 스레드 A가 접근하면 공유 자원에 락을 걸어 스레드 B가 접근하지 못하게 만든다. 스레드 A의 작업이 종료되면 락을 풀고 ( = release = unlock) 대기(wait) 중이던 스레드 B가 작업을 수행하게 만든다.
이렇게 스레드를 순차적으로 실행하게 만들면 공유 자원의 동기화를 구현할 수 있다. 여기에 사용되는 Lock의 종류 중 하나가 바로 오늘의 주제인 Spinlock 이다.
Spinlock (스핀락)
스레드가 락을 얻을 때까지 무한 루프를 돌며 확인하는 동기화 매커니즘
위에서 설명한 동기화 매커니즘의 원리를 다시 풀어보자. 먼저 스레드가 실행되는 동안 (= CPU를 점유하는 동안) 공유 자원에 락을 걸고, 스레드의 작업이 종료되면 락을 해제한다. 따라서 다음 스레드가 CPU를 차지하기 위해선 공유 자원에 락이 걸렸는지 걸리지 않았는지를 파악하는 과정이 필요하다.
스핀락은 대기 중인 스레드가 공유 자원의 상태를 무한 루프를 이용해 확인하는 방식이다. 락이 걸려있으면 작업하지 못하고, 락이 걸려있지 않다면 작업할 수 있으니 그냥 무작정 반복적으로 Lock이 반환될 때까지 확인하며 대기하는 것이다.
이러한 스핀락은 OS의 스케줄링 지원을 받지 않기에, 해당 스레드에 대한 context switching (문맥 교환)이 일어나지 않는다는 특징이 있다.
Context switching
: 하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하기 위해 이전 프로세스의 문맥을 보관하고 새로운 프로세스의 상태를 적재하는 작업
스핀락의 장단점
😎 장점
위에서 스핀락은 스레드가 대기 상태로 전환되지 않기에 문맥 교환이 일어나지 않는 특징을 갖는다고 언급했다. 따라서 다음의 장점을 갖는다.
- 문맥 교환에 필요한 CPU의 오버헤드를 줄일 수 있다 (문맥 교환 중엔 어떤 작업을 수행할 수 없음)
- 락의 획득이 빠르다 (무한 루프 속에서 반복해서 락을 확인하기 때문)
🤥 단점
스핀락의 정의를 보자. 락을 획득할 때까지 무한 루프를 도는 친구다. 이 작업 자체가 CPU를 많이 잡아먹는다는 단점이 있다. 임계 영역이 한 두개가 아니라 여러 개라면? 또 락이 반환될 때까지 오랜 시간이 걸린다면? 따라서 다음의 단점을 갖는다.
- Busy waiting : 스핀락의 획득을 위해 CPU의 오버헤드가 발생할 수 있다. (무한루프를 돌면서 CPU를 계속 사용함)
- Starvation (기아 상태) : 특정 스레드나 프로세스가 공유 자원을 오랫동안 점유한다면, 다른 스레드들이 대기 상태에 갇힐 수 있다.
적용
💡 스핀락은 스레드나 프로세스의 경합 상황이 짧을 때 ( = 임계 구역에서의 작업이 빠르게 이루어질 때) 유용하다.
⚡️ 스핀락의 무한 루프 덕분에 락의 획득과 반환이 빨라 실행 속도도 빨라지고, 문맥 교환이 생략되기에 CPU의 오버헤드도 줄어든다.
💡 스핀락은 여러 개의 CPU 코어가 존재할 때 유용하다.
⚡️ 사용하지 않는 CPU 코어에서 스핀락을 통해 대기하다가 바로 락을 획득할 수 있다. (사실 단일 코어일 땐 스핀락이 의미가 없기도 하고..!)
트레이드 오프를 고려하여, 경합 상황이 길거나 싱글 CPU일 경우엔 다른 동기화 메커니즘 (ex. 뮤텍스, 세마포어 등)을 고려해보자.
레퍼런스
문맥 교환 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. -->
ko.wikipedia.org
스핀락 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 스핀락(spinlock)은 임계 구역(critical section)에 진입이 불가능할 때 진입이 가능할 때까지 루프를 돌면서 재시도하는 방식으로 구현된 락을 가리킨다. 스핀락이라
ko.wikipedia.org
- 프로세스 동기화 : https://rebro.kr/176
[운영체제(OS)] 6. 프로세스 동기화(Process Synchronization)
[목차] 1. Race Condition 2. Critical Section 3. Synchronization Algorithms 4. Synchronization Hardware 5. Mutex Locks 6. Semaphores 7. Classical Problems of Synchronization 8. Monitor 참고) - https://parksb.github.io/article/10.html - KOCW 공개강의
rebro.kr