

개요
프로젝트를 하다보면 count를 자주 사용하게 된다. 게시글의 수, 댓글의 수, 친구 수, 알림 수, 통계 처리 등 아주 다양한 count 요구사항이 존재한다. Spring JPA를 사용하면 count 키워드 (쿼리 메소드)를 이용해 아주 쉽게 해당 기능을 구현할 수 있다.
하지만 우리가 무심코 사용하는 count 쿼리, 과연 데이터 수가 많을 때에도, 그리고 request 수가 (또는 TPS) 많을 때에도 잘 작동할까? count 를 구현하는 5가지 방법들과, 각각의 장단점을 알아보자.
개발 환경
1. Framework : Spring Boot 2.6
2. Programming Language : Java 11
3. DataBase : MySQL 8
4. OS : macOS Ventura 13.2.1
5. IDE : IntelliJ & DataGrip
데이터가 많은 환경을 가정하기 위해 프로시저를 사용해 더미 데이터를 넣은 상태로 진행했다. 더미데이터 insert 방법은 더보기 참고!
1. user, post, comment 테이블 생성 (테스트를 위한 테이블이므로, 대강 만들어주었습니다.)



2. user 테이블에 더미 데이터를 넣는다.
DELIMITER $$ -- 구문의 끝을 나타내는 문자 정의 (여기서는 $$)
DROP PROCEDURE IF EXISTS insertLoop$$ -- 'insertLoop'라는 프로시저가 있으면 드랍
CREATE PROCEDURE insertLoop() -- 'insertLoop' 프로시저 생성
BEGIN -- 단위 블럭 시작
DECLARE i INT DEFAULT 1;
WHILE i <= 50000 DO -- 단위 블럭 2 시작
INSERT INTO test.user(name) VALUES (concat('user',i));
SET i = i + 1;
END WHILE; -- 단위 블럭 2 종료
END$$ -- 단위 블럭 종료
DELIMITER ; -- 구문의 끝을 나타내는 문자 정의 (여기서는 ;)
CALL insertLoop; -- 생성한 프로시저 호출BEGIN와 END 사이에 일반적인 프로그래밍 언어로 코딩하든 원하는 로직을 넣으면 된다. 위의 코드는 i가 50000이 될 때까지 user 테이블에 'user' + i 이름값을 갖는 레코드를 insert하는 프로시저이다.
만약 프로시저 짜는게 어렵다면 이런 사이트 등을 이용할 수 있는데, 무료 버전은 개수가 제한되기 때문에 오히려 번거로울 수 있다는 점 참고하자.
3. 동일하게, post 테이블과 comment 테이블에도 더미 데이터를 넣는다.
DELIMITER $$
DROP PROCEDURE IF EXISTS insertLoop$$
CREATE PROCEDURE insertLoop()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE j INT DEFAULT 1;
WHILE j <= 50000 DO
SET i = 1; -- 내부 반복문을 시작하기 전에 i의 초기값을 1로 설정합니다.
WHILE i <= 50000 DO
INSERT INTO test.comment(user_id, content, post_id)
VALUES (i, concat('content', 1), j);
SET i = i + 1;
END WHILE;
SET j = j + 1000;
END WHILE;
END$$
DELIMITER $$
CALL insertLoop;
$$comment는 좀 더 많이 넣어주었다. 코드 그대로, j가 50000이 될 때까지 1000씩 증가하면서 j를 id로 갖는 포스트에 5만개의 comment를 추가해준다. 시간이 은근 걸리니 주의!
4. 테이블 용량 확인
SELECT
concat(table_schema,'.',table_name) AS "table",
concat(round(data_length/(1024*1024),2), 'MB') AS data,
concat(round(index_length/(1024*1024),2), 'MB') AS idx,
concat(round((data_length+index_length)/(1024*1024),2), 'MB') AS total_size,
round(index_length/data_length,2) idxfrac
FROM
information_schema.TABLES
WHERE
table_rows is not null and TABLE_SCHEMA = 'test' and TABLE_NAME = 'comment';결과적으로, count의 대상이 될 comment 테이블의 스펙은 아래와 같다.
| 이름 | 컬럼 수 | FK 수 | 전체 row 수 | 테이블 용량 | 인덱스 수 | 인덱스 용량 |
| comment | 4 | 2 (user, post) | 2,550,000 | 0.02MB | 3 (PK, FK) | 0MB |
(PK, FK에 대해서 분명 자동으로 인덱스가 생겼는데, 용량이 0인건 인덱스 사이즈가 KB 단위로 작아서 인 것 같다. 아마도..?)
1. count 쿼리 이용하기 (index X)
비교를 위해 FK를 일시적으로 드랍하고, FK 인덱스도 삭제해주었습니다.
1️⃣ 전체 comment을 count 한 경우
public Long countAll() {
long start1 = System.currentTimeMillis();
Long count = commentRepo.count();
long end1 = System.currentTimeMillis();
System.out.println("쿼리 실행시간: " + (end1 - start1) + " ms");
return count;
}
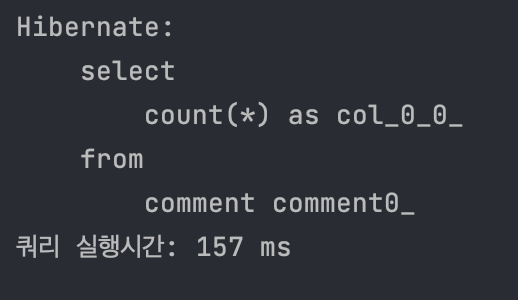
postman에 네트워크 통신 시간이 포함되어 있다고 가정했을 때, 쿼리 실행 시간은 157ms
(id는 PK라 무조건 인덱스가 생성되고 drop할 수 없다. 전체 count가 id를 이용한다고 가정하면 인덱스를 탔다고 생각할 수 있다.)
2️⃣ 특정 post의 comment를 count 한 경우
public Long countByPostId(Integer postId) {
long start1 = System.currentTimeMillis();
Long count = commentRepo.countAllByPostId(postId);
long end1 = System.currentTimeMillis();
System.out.println("쿼리 실행시간: " + (end1 - start1) + " ms");
return count;
}
public interface CommentRepo extends JpaRepository<Comment, Integer> {
Long countAllByPostId(Integer postId);
}
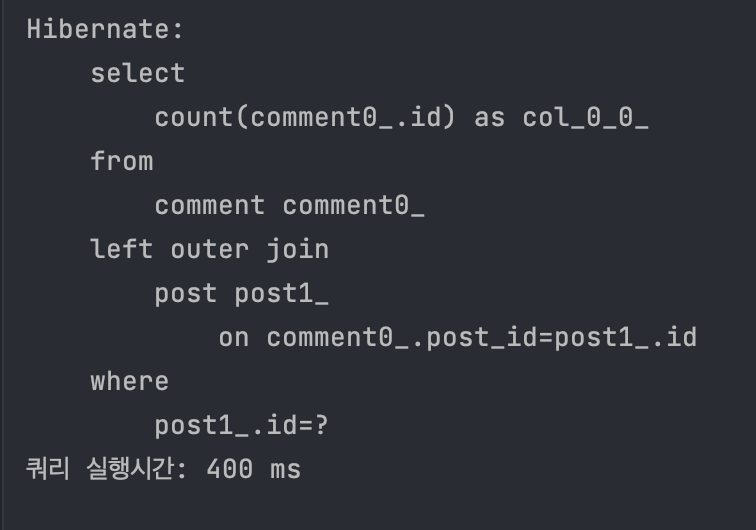
마찬가지로, 쿼리 실행 시간은 쿼리 전후로 시간을 측정해서 얻은 400ms.
2. count 쿼리 이용하기 (index O)
이번엔 1에서 drop한 FK를 다시 추가했다. FK에 의해 post index도 생긴 상태에서 다시 한번 동일한 코드를 실행하면?
1️⃣ 전체 comment을 count 한 경우

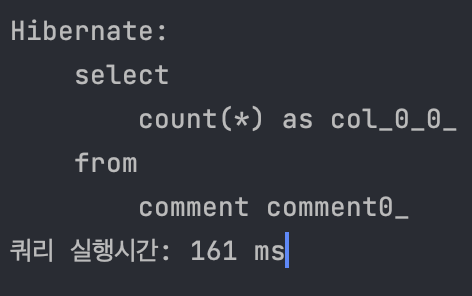
1과 결과 차이가 별로 나지 않는 것을 보니, 역시 1과 동일한 실행 계획을 따르는 것 같다.
2️⃣ 특정 post의 comment를 count 한 경우
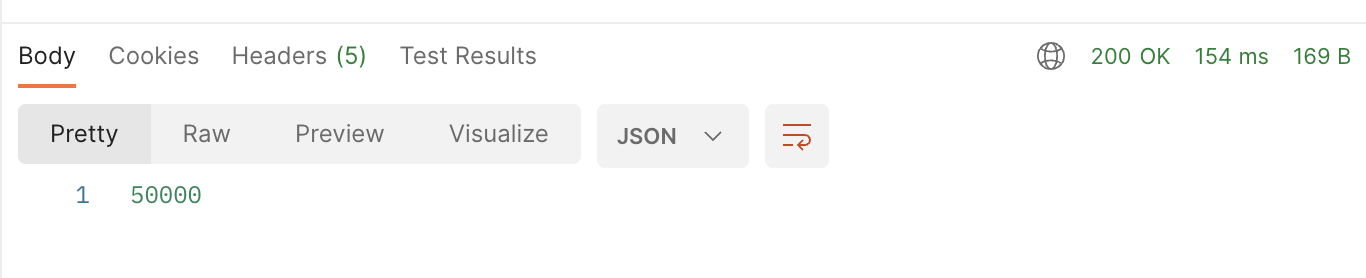
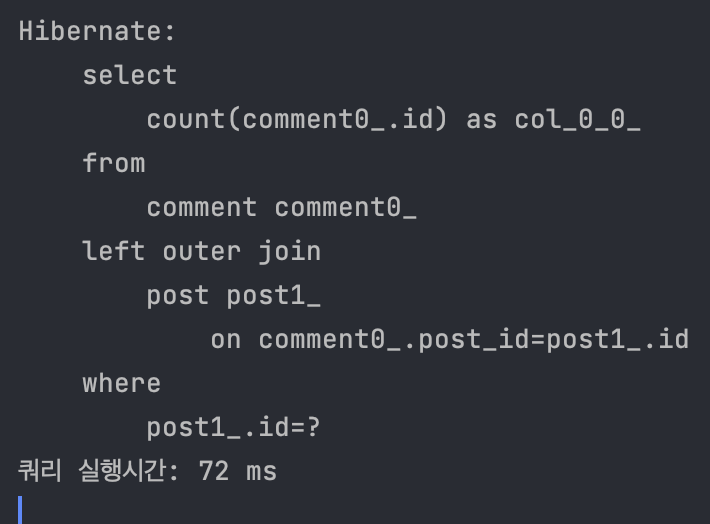
전체 API call 시간은 499ms -> 154ms로, 쿼리 실행 시간은 400ms -> 72ms로 꽤 드라마틱하게 줄었다!
역시 쿼리 튜닝의 절반은 인덱스라는 것을 다시 한 번 깨달을 수 있었다 👍
하지만 위 예제는 컬럼도 몇 개 없고, FK를 이용한 아주 예쁜 케이스의 경우이다. 컬럼이 아주 많다면? 그래서 인덱스가 여러개라면? 복합 인덱스를 걸어야 한다면? 카디널리티가 낮다면? 인덱스 사이즈가 너무 커져서 디스크 I/O 성능 저하가 발생한다면? 또는 쿼리 조회 속도는 빠르지만, 해당 결과물로 서비스 단에서 별도의 연산 처리가 또 필요하다면?
극단적인 예시지만, 어쨌든 인덱스를 걸더라도 조회 속도가 느릴 수 있다. 이런 경우엔 캐시를 고려해보자.
3. count 결과물에 캐시 적용하기
캐시 (Cache)
이전에 요청한 연산 처리 결과를 저장해두었다가, 동일한 요청이 왔을 때 별도의 연산 없이 바로 결과를 돌려주는 것.
DB (디스크) 영역은 접근하려면 숨참고 딥다이브해서 깊게 들어가야 하는데,
캐시는 디스크보다 위에 있어 호다닥 다녀올 수 있어 빠르다고 생각하면 된다.
스프링에서 캐시를 다루는 방법은 글로벌 캐시, 로컬 캐시 등 다양하게 있지만 이번 포스팅은 캐시가 아니라 count를 다루는 포스팅이니 간단히 넘어가겠다. 로컬 캐시 라이브러리인 EHCache를 이용해 2의 쿼리 조회 결과물에 캐시를 적용해보겠다.
EHCache 적용 방법은 더보기 참고!
1. gradle.build 에 dependency 추가
// ehcache
implementation "org.springframework.boot:spring-boot-starter-cache"
implementation group: 'net.sf.ehcache', name: 'ehcache', version: '2.10.9.2'
implementation "javax.cache:cache-api:1.0.0"
2. 스프링 부트 메인 어플리케이션에 @EnableCaching 추가
@EnableCaching
@SpringBootApplication
public class Main {
public static void main(String[] args) {
SpringApplication.run(Main.class, args);
}
}
3. 캐시 설정 파일 설정
공식 문서 에 자세한 설명이 나와있으니 참고하세요!
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<diskStore path="java.io.tmpdir" />
<cache name="count"
maxEntriesLocalHeap="500"
maxEntriesLocalDisk="500"
eternal="false"
diskSpoolBufferSizeMB="20"
timeToIdleSeconds="1800" timeToLiveSeconds="1800"
memoryStoreEvictionPolicy="LFU"
transactionalMode="off">
<persistence strategy="localTempSwap" />
</cache>
</ehcache>
4. CacheConfig 만들어서 xml 설정 리소스 생성
@EnableCaching
@Configuration
public class CacheConfig {
@Bean
public EhCacheManagerFactoryBean ehCacheManagerFactoryBean() {
EhCacheManagerFactoryBean ehCacheManagerFactoryBean = new EhCacheManagerFactoryBean();
ehCacheManagerFactoryBean.setConfigLocation(new ClassPathResource("ehcache.xml"));
ehCacheManagerFactoryBean.setShared(true);
return ehCacheManagerFactoryBean;
}
@Bean
public EhCacheCacheManager ehCacheCacheManager(EhCacheManagerFactoryBean ehCacheManagerFactoryBean) {
EhCacheCacheManager ehCacheCacheManager = new EhCacheCacheManager();
ehCacheCacheManager.setCacheManager(ehCacheManagerFactoryBean.getObject());
return ehCacheCacheManager;
}
}new ClassPathResource에는 3에서 만든 xml 파일의 이름을 적어줘야 한다.
5. application.yml에 xml 추가
spring:
# 실행할 프로필 정보
profiles:
active: local
# cache
cache:
jcache:
config: ehcache.xml
6. 메소드에 캐싱 처리
@Cacheable(cacheNames = "count")
public Long countByPostId(Integer postId) {
long start1 = System.currentTimeMillis();
Long count = commentRepo.countAllByPostId(postId);
long end1 = System.currentTimeMillis();
System.out.println("쿼리 실행시간: " + (end1 - start1) + " ms");
return count;
}cacheNames에는 ehcache.xml에서 지정한 cache name을 넣어주어야 한다.
1️⃣ 첫 호출의 경우 (캐시 사용 X)

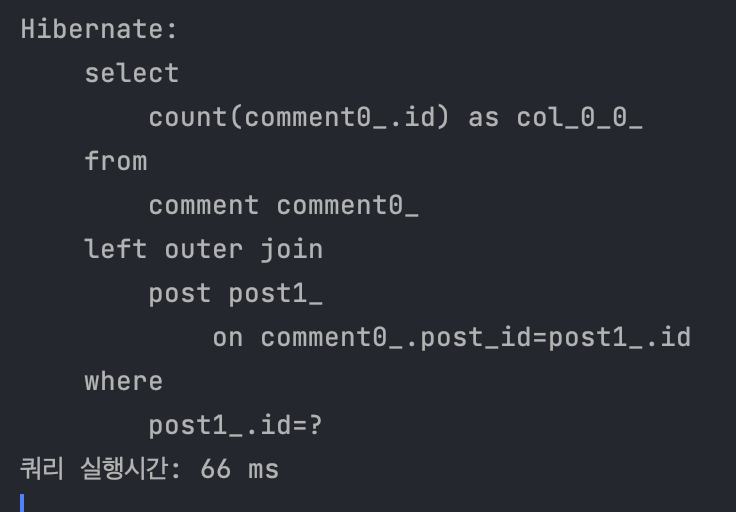
2️⃣ 두번째 호출의 경우 (캐시 사용 O)
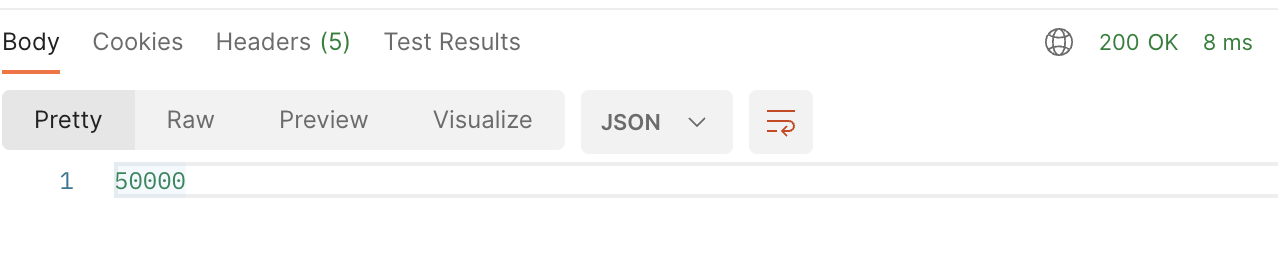
캐시 사용 전 145ms -> 캐시 사용 후 8ms로 성능이 향상되었다. 쿼리 캐시 아냐?! 라고 생각할 수 있지만, 로그에 쿼리가 아예 찍히지 않았으므로 쿼리를 이용해 결과를 얻은게 아니라 저장해두었던 캐시에서 값을 가져왔음을 확인할 수 있다.
이렇게 보면 캐시가 아주 드라마틱해보이고, 앞으로 생기는 모든 성능 문제에 캐시를 적용하면 될 것 처럼 보인다. 하지만 캐시는 만능이 아니다. TTL도 생각해줘야하고, 만약 데이터의 CUD가 활발하다면 캐시도 계속 업데이트 쳐주어야 한다. 또 캐시 내부가 꼬일 경우 디버깅도 어렵다.
만약 내가 count 하려는 데이터가 통계용 데이터같이 자주 CUD가 발생하지 않는 값이라면 캐시를 적용하는 건 좋은 해결책이 될 것이다. 하지만 실시간으로 업데이트가 잦은 데이터라면 (ex. 좋아요 기능 등) 캐시를 사용하는 것은 적절하지 않아 보인다.
또 조건을 들어 count하는게 아니라, 테이블에 있는 모든 값을 count해야 한다면? 조건을 들어 count 하더라도 레코드 수가 너무 많아 쿼리 속도가 느리다면? 사실 캐시는 근본적인 해결은 아니고 문제를 커버해보려는 수단이다. 이번엔 별도의 컬럼을 이용해 근본적인 쿼리 속도 문제를 해결해보자.
4. count 수 관리하는 컬럼 이용하기
이게 몬소리냐? 간단하다. 매번 count 쿼리를 날리는게 아니라, count 수를 관리하는 컬럼을 두고, insert / delete 요청이 들어올 때마다 +1 또는 -1을 쳐주는 것이다. 본 포스팅은 게시글에 달린 댓글 수를 세고 있으므로, post 테이블을 아래와 같이 수정하자.

DB에서 trigger를 이용해도 되지만, 그보단 어플리케이션 (서버 단)에서 처리해주는게 좀 더 관리가 편할 것이다. (trigger 사용은 보통 피하는 편이더라. 정확히 어떤 이유인지 나중에 찾아봐야겠다 🤔)
예를 들면, POST /api/post/{postId}/comment로 특정 포스트에 신규 코멘트 추가 요청이 들어오면, 해당 post record의 comment_count에 +1을 해 준다.
반대로, DELETE /api/post/{postId}/comment/{commentId}로 특정 포스트에 달린 코멘트를 삭제하라는 요청이 들어오면, 해당 post의 comment_count에 -1을 해 준다.
public Integer getCommentCountByPostId(Integer postId) {
long start1 = System.currentTimeMillis();
Integer count = postRepo.getCommentCountById(postId);
long end1 = System.currentTimeMillis();
System.out.println("쿼리 실행시간: " + (end1 - start1) + " ms");
return count;
}
public interface PostRepo extends JpaRepository<Post, Integer> {
@Query("select p.commentCount from Post p where p.id = :postId")
Integer getCommentCountById(@Param("postId") Integer postId);
}
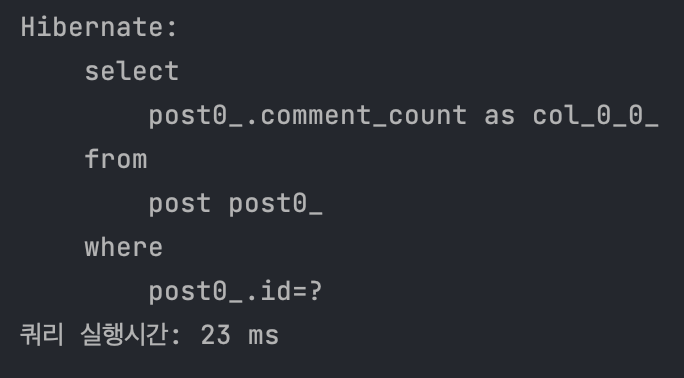
캐시를 적용했을 때 만큼은 아니지만, 그래도 꽤 속도가 빨라졌다! (전체 API call 시간은 154ms -> 109ms로, 쿼리 실행 시간은 72ms -> 23ms) 레코드 수가 많아질 수록, 그러니까 count 결과물이 많아질 수록 이 성능 차이는 점점 커질 것이다.
캐시를 적용하기 어려운 환경일때, 그리고 전체 레코드 수가 많고 다양한 연산이 수행되어 섣불리 튜닝을 하기 어려운 환경일 때 적용하기 좋은 방법일 것 같다. update where 문을 사용하면 되므로 기존 테이블에 새로 컬럼을 추가하기도 간편하고! (ddl이라 운영 중에는 무리겠지만)
하지만 이 방법에도 문제가 있다. 일단 구현 단계에서 생각해보자.
- select로 특정 post 엔티티를 조회한다.
- comment를 save 한다.
- save에 성공했다면, 1에서 가져온 엔티티를 이용해 post의 comment_count 값에 +1을 해준다.
이렇게 구현하면 된다고 생각했다면, 아마 높은 확률로 운영 환경에서 count 값이 엉망 진창이 될 것이다. 다수의 유저가 동시에 comment를 남기는 상황을 고려하지 않았기 때문이다. 예를 들어보자.
- A 사용자가 comment 추가 요청을 보낸다 -> 이때 post의 commment_count 수는 5이다.
- 이때 B 사용자도 comment 추가 요청을 보낸다 -> A 사용자의 comment가 save 되기 전이므로 post의 comment_count는 마찬가지로 5이다.
- A와 B 사용자는 comment를 save한 후, post.commentCount += 1 로 코멘트 수를 1씩 증가시켜준다.
- 결과적으로 새로운 코멘트는 2개가 추가되었으나, post의 comment_count 수는 7이 아니라 6이 된다.
트랜잭션, 동시성 제어에서 많이들 이야기하는 갱신 손실 문제 (Lost update) 문제가 발생하는 것이다. 이를 해결하기 위해선 특정 트랜잭션 처리가 종료될 때까지 다른 트랜잭션은 접근하지 못하게 락을 걸어주거나, update select 문을 이용하는 방법을 고려할 수 있다.
하지만 이 두 가지 방법은 특정 record를 묶어두는 방법이기에, 사용자가 많다면, 요청이 많다면 성능이 매우 나빠질 것이다. 무작정 기다려야 하기 때문이다! 내가 인스타그램에서 아리아나 그란데의 게시물에 댓글을 남긴다고 가정해보자. 나 말고도 전세계의 아리아나 팔로워들이 실시간으로 댓글을 남기고 있을 것이다. 내가 엔터를 치고 5분이 지나서야 댓글이 남겨진다면 얼마나 끔찍하겠는가?
이건 좀 과장한 예시이긴 하지만, 어쨌든 서비스의 확장성과 성능을 고려했을 때 락은 쉽게 선택할 만한 선택지는 아니다. 문제가 생겼을 때 해결할 것을 생각하면 더더욱. 그래서 이에 대해 고민하다가, DBA 오픈 채팅방에 질문을 남겼다. 그리고 새로운 선택지를 알게 되었다! 😎
새로 들은 방법은 sequence 기능인데, 유일한 값을 생성해주는 객체로, 순차적으로 증가하는 컬럼을 자동으로 생성해주는 친구다. 해당 기능은 oracle에서는 지원하지만 mysql에서는 지원하지 않아 프로시저를 이용해 꽤 번거롭게 직접 구현해야 했다.

오엠지.. 그러다 꼭 실시간이 아니라, 집계성으로 처리하는 방법도 있다는 의견에 힌트를 얻었다.

다시 아리아나 그란데의 예시로 넘어가자. 전세계의 아리아나 팬은 아주 많다. 그리고 생각해보면, 인스타그램은 아리아나의 팔로워를 아주 정확하게 표현하기보단 대강 추려서 표현한다. (근데 게시글 좋아요 수랑 댓글 수는 또 세세한걸 보니 그냥 UI 기획상의 표현일 수도 있다ㅎ)

이처럼, 팔로워 수가 3.7억 언저리라는 것만 알면 되는 경우엔 count 결과가 꼭 정확하게 맞을 필요가 없다. 그럼 평소 CD 요청이 들어올 때는 해당 값만 잘 처리해주고, 나중에 배치 등을 활용에 싱크를 맞춰주는 방법은 어떨까?
5. Batch를 이용해 Sync 맞춰주기
우아한 형제들의 테코블에서는 이렇게 시간이 지난 후 최종적으로 데이터를 동기화해서 궁극적 일관성(Eventual Consistency)를 지키는 방법을 Sync Schedule로 표현했다. 말 그대로 데이터의 싱크를 맞춰주는 스케줄러를 의미하는 것 같다.
구현하는 방법 자체는 개인의 환경에 맞춰 생각하면 되는데, 나는 일단 Batch와 스케줄러를 이용하는 방법을 생각했다. 4번 방법을 함께 사용하고, 특정 주기마다 스케줄러를 돌면서 배치를 이용해 싱크를 맞춰주는 방식이다.
4번 방법의 문제는 사용자와 요청이 많을 때 발생하고, 사용자가 많다면 1의 자리까지 세세한 숫자는 중요도가 덜하다는 부분에서 착안하여 비실시간으로 정확한 count 개수를 업데이트 해주는 방법이다. 이렇게 하면, 4번 방법에서 예시를 들었던 이슈 (기존 코멘트 5개 있는 상황에 2명이 새로 코멘트를 남겼는데 결과가 6) 도 스케줄러에서 싱크가 맞춰지니 (댓글 수 직접 count 해서 6을 7로 업데이트 쳐준다) 문제가 해결된다.
실시간이 아니라는 점에서 기획상 문제가 될 수 있지만, 락 발생 가능을 줄이고, DB 부담을 덜어준다는 점에서 레코드 수가 아주 많을 땐 한번 쯤 고려해볼 만한 방법인 것 같다 👀
마무리
오늘은 count를 구현하는 다양한 방법에 대해 고민해보았다. 평소엔 아무 생각없이 JPARepository를 이용해 count 키워드를 남발했는데, 이번 포스팅을 위해 이것 저것 찾아보며 count도 경우에 따라 많은 고민이 필요하다는 점을 배울 수 있었다.
count 서비스의 정확한 용도, 캐시와 같은 부차적인 서비스의 도입 여부, 현재 시스템 아키텍처, 실시간성 여부 등 프로젝트의 다양한 점을 고민해보고 팀원들과 소통하며 서비스에 적합한 방법을 찾아나가는게 서버 개발자의 역할이라고 생각한다.
다음엔 count를 구현할 때 팀원들과 이 기능에서 발생할 수 있는 문제가 무엇이 있는지 한번 토론해본 후 개발에 들어가야겠다 😎
레퍼런스
- Mysql 테이블 용량 구하기 : https://ryean.tistory.com/21
[MySQL] 데이터베이스 및 테이블별 용량 (Size by databases and tables) 조회
데이터베이스별, 테이블별, 전체 용량을 아래 쿼리를 통해 확인 할 수 있다. 1. 데이터베이스별 용량 (Database Size) 조회 SELECT table_schema AS 'DatabaseName', ROUND(SUM(data_length+index_length)/1024/1024, 1) AS 'Size(MB
ryean.tistory.com
- Spring EHcache 적용하기 : https://juhi.tistory.com/66
[Spring] EHcache를 이용해 캐시 간단하게 적용하기 (feat. @ Cacheable)
자주 바뀌는 값이 아닌데, 데이터베이스에 접근해서 가져오는데 시간이 걸려서 불편할 때가 있다. 이럴 때 간단하게 서버 단에서 캐시로 들고 있을 수 있다. 필요성 데이터 중 매번 실시간 데이
juhi.tistory.com
- 트랜잭션 및 동시성 제어 : https://quantum-jumpin.tistory.com/9
[Database] 트랜잭션 및 동시성 제어
분명 동시에 같은 곳에 요청을 하는 작업이 많을 것 같은데 데이터 베이스는 이걸 어떻게 처리할까 그래서 찾아본 결과를 정리해봤다. 먼저 동시성 제어를 알려면 트랜잭션에 대해 알아야 한다
quantum-jumpin.tistory.com
- 좋아요 개수 조회 최적화하기 : https://tecoble.techcourse.co.kr/post/2022-10-10-like-count/
좋아요 개수 조회 최적화하기
속닥속닥 프로젝트(https://github.com/woowacourse-teams/2022-sokdak…
tecoble.techcourse.co.kr
'Develop > Spring' 카테고리의 다른 글
| [Spring Boot] 자바 스프링에서 처리율 제한 기능을 구현하는 4가지 방법 (2) | 2023.06.21 |
|---|---|
| [Spring Boot] Jsoup으로 OG태그 메타 데이터 크롤링하기 (1) | 2023.06.14 |
| [Spring Boot] ConstraintValidator를 이용해 나만의 validator annotation 만들기 (1) | 2023.05.15 |
| [Spring Boot] 테스트 컨테이너로 테스트하기 (3) | 2023.04.17 |
| [Spring Boot 3] SpringDoc과 Swagger를 이용해 API 문서화 자동화하기 (5) | 2023.03.21 |
개요
프로젝트를 하다보면 count를 자주 사용하게 된다. 게시글의 수, 댓글의 수, 친구 수, 알림 수, 통계 처리 등 아주 다양한 count 요구사항이 존재한다. Spring JPA를 사용하면 count 키워드 (쿼리 메소드)를 이용해 아주 쉽게 해당 기능을 구현할 수 있다.
하지만 우리가 무심코 사용하는 count 쿼리, 과연 데이터 수가 많을 때에도, 그리고 request 수가 (또는 TPS) 많을 때에도 잘 작동할까? count 를 구현하는 5가지 방법들과, 각각의 장단점을 알아보자.
개발 환경
1. Framework : Spring Boot 2.6
2. Programming Language : Java 11
3. DataBase : MySQL 8
4. OS : macOS Ventura 13.2.1
5. IDE : IntelliJ & DataGrip
데이터가 많은 환경을 가정하기 위해 프로시저를 사용해 더미 데이터를 넣은 상태로 진행했다. 더미데이터 insert 방법은 더보기 참고!
1. user, post, comment 테이블 생성 (테스트를 위한 테이블이므로, 대강 만들어주었습니다.)
2. user 테이블에 더미 데이터를 넣는다.
DELIMITER $$ -- 구문의 끝을 나타내는 문자 정의 (여기서는 $$)
DROP PROCEDURE IF EXISTS insertLoop$$ -- 'insertLoop'라는 프로시저가 있으면 드랍
CREATE PROCEDURE insertLoop() -- 'insertLoop' 프로시저 생성
BEGIN -- 단위 블럭 시작
DECLARE i INT DEFAULT 1;
WHILE i <= 50000 DO -- 단위 블럭 2 시작
INSERT INTO test.user(name) VALUES (concat('user',i));
SET i = i + 1;
END WHILE; -- 단위 블럭 2 종료
END$$ -- 단위 블럭 종료
DELIMITER ; -- 구문의 끝을 나타내는 문자 정의 (여기서는 ;)
CALL insertLoop; -- 생성한 프로시저 호출BEGIN와 END 사이에 일반적인 프로그래밍 언어로 코딩하든 원하는 로직을 넣으면 된다. 위의 코드는 i가 50000이 될 때까지 user 테이블에 'user' + i 이름값을 갖는 레코드를 insert하는 프로시저이다.
만약 프로시저 짜는게 어렵다면 이런 사이트 등을 이용할 수 있는데, 무료 버전은 개수가 제한되기 때문에 오히려 번거로울 수 있다는 점 참고하자.
3. 동일하게, post 테이블과 comment 테이블에도 더미 데이터를 넣는다.
DELIMITER $$
DROP PROCEDURE IF EXISTS insertLoop$$
CREATE PROCEDURE insertLoop()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE j INT DEFAULT 1;
WHILE j <= 50000 DO
SET i = 1; -- 내부 반복문을 시작하기 전에 i의 초기값을 1로 설정합니다.
WHILE i <= 50000 DO
INSERT INTO test.comment(user_id, content, post_id)
VALUES (i, concat('content', 1), j);
SET i = i + 1;
END WHILE;
SET j = j + 1000;
END WHILE;
END$$
DELIMITER $$
CALL insertLoop;
$$comment는 좀 더 많이 넣어주었다. 코드 그대로, j가 50000이 될 때까지 1000씩 증가하면서 j를 id로 갖는 포스트에 5만개의 comment를 추가해준다. 시간이 은근 걸리니 주의!
4. 테이블 용량 확인
SELECT
concat(table_schema,'.',table_name) AS "table",
concat(round(data_length/(1024*1024),2), 'MB') AS data,
concat(round(index_length/(1024*1024),2), 'MB') AS idx,
concat(round((data_length+index_length)/(1024*1024),2), 'MB') AS total_size,
round(index_length/data_length,2) idxfrac
FROM
information_schema.TABLES
WHERE
table_rows is not null and TABLE_SCHEMA = 'test' and TABLE_NAME = 'comment';결과적으로, count의 대상이 될 comment 테이블의 스펙은 아래와 같다.
| 이름 | 컬럼 수 | FK 수 | 전체 row 수 | 테이블 용량 | 인덱스 수 | 인덱스 용량 |
| comment | 4 | 2 (user, post) | 2,550,000 | 0.02MB | 3 (PK, FK) | 0MB |
(PK, FK에 대해서 분명 자동으로 인덱스가 생겼는데, 용량이 0인건 인덱스 사이즈가 KB 단위로 작아서 인 것 같다. 아마도..?)
1. count 쿼리 이용하기 (index X)
비교를 위해 FK를 일시적으로 드랍하고, FK 인덱스도 삭제해주었습니다.
1️⃣ 전체 comment을 count 한 경우
public Long countAll() {
long start1 = System.currentTimeMillis();
Long count = commentRepo.count();
long end1 = System.currentTimeMillis();
System.out.println("쿼리 실행시간: " + (end1 - start1) + " ms");
return count;
}postman에 네트워크 통신 시간이 포함되어 있다고 가정했을 때, 쿼리 실행 시간은 157ms
(id는 PK라 무조건 인덱스가 생성되고 drop할 수 없다. 전체 count가 id를 이용한다고 가정하면 인덱스를 탔다고 생각할 수 있다.)
2️⃣ 특정 post의 comment를 count 한 경우
public Long countByPostId(Integer postId) {
long start1 = System.currentTimeMillis();
Long count = commentRepo.countAllByPostId(postId);
long end1 = System.currentTimeMillis();
System.out.println("쿼리 실행시간: " + (end1 - start1) + " ms");
return count;
}
public interface CommentRepo extends JpaRepository<Comment, Integer> {
Long countAllByPostId(Integer postId);
}마찬가지로, 쿼리 실행 시간은 쿼리 전후로 시간을 측정해서 얻은 400ms.
2. count 쿼리 이용하기 (index O)
이번엔 1에서 drop한 FK를 다시 추가했다. FK에 의해 post index도 생긴 상태에서 다시 한번 동일한 코드를 실행하면?
1️⃣ 전체 comment을 count 한 경우
1과 결과 차이가 별로 나지 않는 것을 보니, 역시 1과 동일한 실행 계획을 따르는 것 같다.
2️⃣ 특정 post의 comment를 count 한 경우
전체 API call 시간은 499ms -> 154ms로, 쿼리 실행 시간은 400ms -> 72ms로 꽤 드라마틱하게 줄었다!
역시 쿼리 튜닝의 절반은 인덱스라는 것을 다시 한 번 깨달을 수 있었다 👍
하지만 위 예제는 컬럼도 몇 개 없고, FK를 이용한 아주 예쁜 케이스의 경우이다. 컬럼이 아주 많다면? 그래서 인덱스가 여러개라면? 복합 인덱스를 걸어야 한다면? 카디널리티가 낮다면? 인덱스 사이즈가 너무 커져서 디스크 I/O 성능 저하가 발생한다면? 또는 쿼리 조회 속도는 빠르지만, 해당 결과물로 서비스 단에서 별도의 연산 처리가 또 필요하다면?
극단적인 예시지만, 어쨌든 인덱스를 걸더라도 조회 속도가 느릴 수 있다. 이런 경우엔 캐시를 고려해보자.
3. count 결과물에 캐시 적용하기
캐시 (Cache)
이전에 요청한 연산 처리 결과를 저장해두었다가, 동일한 요청이 왔을 때 별도의 연산 없이 바로 결과를 돌려주는 것.
DB (디스크) 영역은 접근하려면 숨참고 딥다이브해서 깊게 들어가야 하는데,
캐시는 디스크보다 위에 있어 호다닥 다녀올 수 있어 빠르다고 생각하면 된다.
스프링에서 캐시를 다루는 방법은 글로벌 캐시, 로컬 캐시 등 다양하게 있지만 이번 포스팅은 캐시가 아니라 count를 다루는 포스팅이니 간단히 넘어가겠다. 로컬 캐시 라이브러리인 EHCache를 이용해 2의 쿼리 조회 결과물에 캐시를 적용해보겠다.
EHCache 적용 방법은 더보기 참고!
1. gradle.build 에 dependency 추가
// ehcache
implementation "org.springframework.boot:spring-boot-starter-cache"
implementation group: 'net.sf.ehcache', name: 'ehcache', version: '2.10.9.2'
implementation "javax.cache:cache-api:1.0.0"
2. 스프링 부트 메인 어플리케이션에 @EnableCaching 추가
@EnableCaching
@SpringBootApplication
public class Main {
public static void main(String[] args) {
SpringApplication.run(Main.class, args);
}
}
3. 캐시 설정 파일 설정
공식 문서 에 자세한 설명이 나와있으니 참고하세요!
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<diskStore path="java.io.tmpdir" />
<cache name="count"
maxEntriesLocalHeap="500"
maxEntriesLocalDisk="500"
eternal="false"
diskSpoolBufferSizeMB="20"
timeToIdleSeconds="1800" timeToLiveSeconds="1800"
memoryStoreEvictionPolicy="LFU"
transactionalMode="off">
<persistence strategy="localTempSwap" />
</cache>
</ehcache>
4. CacheConfig 만들어서 xml 설정 리소스 생성
@EnableCaching
@Configuration
public class CacheConfig {
@Bean
public EhCacheManagerFactoryBean ehCacheManagerFactoryBean() {
EhCacheManagerFactoryBean ehCacheManagerFactoryBean = new EhCacheManagerFactoryBean();
ehCacheManagerFactoryBean.setConfigLocation(new ClassPathResource("ehcache.xml"));
ehCacheManagerFactoryBean.setShared(true);
return ehCacheManagerFactoryBean;
}
@Bean
public EhCacheCacheManager ehCacheCacheManager(EhCacheManagerFactoryBean ehCacheManagerFactoryBean) {
EhCacheCacheManager ehCacheCacheManager = new EhCacheCacheManager();
ehCacheCacheManager.setCacheManager(ehCacheManagerFactoryBean.getObject());
return ehCacheCacheManager;
}
}new ClassPathResource에는 3에서 만든 xml 파일의 이름을 적어줘야 한다.
5. application.yml에 xml 추가
spring:
# 실행할 프로필 정보
profiles:
active: local
# cache
cache:
jcache:
config: ehcache.xml
6. 메소드에 캐싱 처리
@Cacheable(cacheNames = "count")
public Long countByPostId(Integer postId) {
long start1 = System.currentTimeMillis();
Long count = commentRepo.countAllByPostId(postId);
long end1 = System.currentTimeMillis();
System.out.println("쿼리 실행시간: " + (end1 - start1) + " ms");
return count;
}cacheNames에는 ehcache.xml에서 지정한 cache name을 넣어주어야 한다.
1️⃣ 첫 호출의 경우 (캐시 사용 X)
2️⃣ 두번째 호출의 경우 (캐시 사용 O)
캐시 사용 전 145ms -> 캐시 사용 후 8ms로 성능이 향상되었다. 쿼리 캐시 아냐?! 라고 생각할 수 있지만, 로그에 쿼리가 아예 찍히지 않았으므로 쿼리를 이용해 결과를 얻은게 아니라 저장해두었던 캐시에서 값을 가져왔음을 확인할 수 있다.
이렇게 보면 캐시가 아주 드라마틱해보이고, 앞으로 생기는 모든 성능 문제에 캐시를 적용하면 될 것 처럼 보인다. 하지만 캐시는 만능이 아니다. TTL도 생각해줘야하고, 만약 데이터의 CUD가 활발하다면 캐시도 계속 업데이트 쳐주어야 한다. 또 캐시 내부가 꼬일 경우 디버깅도 어렵다.
만약 내가 count 하려는 데이터가 통계용 데이터같이 자주 CUD가 발생하지 않는 값이라면 캐시를 적용하는 건 좋은 해결책이 될 것이다. 하지만 실시간으로 업데이트가 잦은 데이터라면 (ex. 좋아요 기능 등) 캐시를 사용하는 것은 적절하지 않아 보인다.
또 조건을 들어 count하는게 아니라, 테이블에 있는 모든 값을 count해야 한다면? 조건을 들어 count 하더라도 레코드 수가 너무 많아 쿼리 속도가 느리다면? 사실 캐시는 근본적인 해결은 아니고 문제를 커버해보려는 수단이다. 이번엔 별도의 컬럼을 이용해 근본적인 쿼리 속도 문제를 해결해보자.
4. count 수 관리하는 컬럼 이용하기
이게 몬소리냐? 간단하다. 매번 count 쿼리를 날리는게 아니라, count 수를 관리하는 컬럼을 두고, insert / delete 요청이 들어올 때마다 +1 또는 -1을 쳐주는 것이다. 본 포스팅은 게시글에 달린 댓글 수를 세고 있으므로, post 테이블을 아래와 같이 수정하자.
DB에서 trigger를 이용해도 되지만, 그보단 어플리케이션 (서버 단)에서 처리해주는게 좀 더 관리가 편할 것이다. (trigger 사용은 보통 피하는 편이더라. 정확히 어떤 이유인지 나중에 찾아봐야겠다 🤔)
예를 들면, POST /api/post/{postId}/comment로 특정 포스트에 신규 코멘트 추가 요청이 들어오면, 해당 post record의 comment_count에 +1을 해 준다.
반대로, DELETE /api/post/{postId}/comment/{commentId}로 특정 포스트에 달린 코멘트를 삭제하라는 요청이 들어오면, 해당 post의 comment_count에 -1을 해 준다.
public Integer getCommentCountByPostId(Integer postId) {
long start1 = System.currentTimeMillis();
Integer count = postRepo.getCommentCountById(postId);
long end1 = System.currentTimeMillis();
System.out.println("쿼리 실행시간: " + (end1 - start1) + " ms");
return count;
}
public interface PostRepo extends JpaRepository<Post, Integer> {
@Query("select p.commentCount from Post p where p.id = :postId")
Integer getCommentCountById(@Param("postId") Integer postId);
}
캐시를 적용했을 때 만큼은 아니지만, 그래도 꽤 속도가 빨라졌다! (전체 API call 시간은 154ms -> 109ms로, 쿼리 실행 시간은 72ms -> 23ms) 레코드 수가 많아질 수록, 그러니까 count 결과물이 많아질 수록 이 성능 차이는 점점 커질 것이다.
캐시를 적용하기 어려운 환경일때, 그리고 전체 레코드 수가 많고 다양한 연산이 수행되어 섣불리 튜닝을 하기 어려운 환경일 때 적용하기 좋은 방법일 것 같다. update where 문을 사용하면 되므로 기존 테이블에 새로 컬럼을 추가하기도 간편하고! (ddl이라 운영 중에는 무리겠지만)
하지만 이 방법에도 문제가 있다. 일단 구현 단계에서 생각해보자.
- select로 특정 post 엔티티를 조회한다.
- comment를 save 한다.
- save에 성공했다면, 1에서 가져온 엔티티를 이용해 post의 comment_count 값에 +1을 해준다.
이렇게 구현하면 된다고 생각했다면, 아마 높은 확률로 운영 환경에서 count 값이 엉망 진창이 될 것이다. 다수의 유저가 동시에 comment를 남기는 상황을 고려하지 않았기 때문이다. 예를 들어보자.
- A 사용자가 comment 추가 요청을 보낸다 -> 이때 post의 commment_count 수는 5이다.
- 이때 B 사용자도 comment 추가 요청을 보낸다 -> A 사용자의 comment가 save 되기 전이므로 post의 comment_count는 마찬가지로 5이다.
- A와 B 사용자는 comment를 save한 후, post.commentCount += 1 로 코멘트 수를 1씩 증가시켜준다.
- 결과적으로 새로운 코멘트는 2개가 추가되었으나, post의 comment_count 수는 7이 아니라 6이 된다.
트랜잭션, 동시성 제어에서 많이들 이야기하는 갱신 손실 문제 (Lost update) 문제가 발생하는 것이다. 이를 해결하기 위해선 특정 트랜잭션 처리가 종료될 때까지 다른 트랜잭션은 접근하지 못하게 락을 걸어주거나, update select 문을 이용하는 방법을 고려할 수 있다.
하지만 이 두 가지 방법은 특정 record를 묶어두는 방법이기에, 사용자가 많다면, 요청이 많다면 성능이 매우 나빠질 것이다. 무작정 기다려야 하기 때문이다! 내가 인스타그램에서 아리아나 그란데의 게시물에 댓글을 남긴다고 가정해보자. 나 말고도 전세계의 아리아나 팔로워들이 실시간으로 댓글을 남기고 있을 것이다. 내가 엔터를 치고 5분이 지나서야 댓글이 남겨진다면 얼마나 끔찍하겠는가?
이건 좀 과장한 예시이긴 하지만, 어쨌든 서비스의 확장성과 성능을 고려했을 때 락은 쉽게 선택할 만한 선택지는 아니다. 문제가 생겼을 때 해결할 것을 생각하면 더더욱. 그래서 이에 대해 고민하다가, DBA 오픈 채팅방에 질문을 남겼다. 그리고 새로운 선택지를 알게 되었다! 😎
새로 들은 방법은 sequence 기능인데, 유일한 값을 생성해주는 객체로, 순차적으로 증가하는 컬럼을 자동으로 생성해주는 친구다. 해당 기능은 oracle에서는 지원하지만 mysql에서는 지원하지 않아 프로시저를 이용해 꽤 번거롭게 직접 구현해야 했다.
오엠지.. 그러다 꼭 실시간이 아니라, 집계성으로 처리하는 방법도 있다는 의견에 힌트를 얻었다.
다시 아리아나 그란데의 예시로 넘어가자. 전세계의 아리아나 팬은 아주 많다. 그리고 생각해보면, 인스타그램은 아리아나의 팔로워를 아주 정확하게 표현하기보단 대강 추려서 표현한다. (근데 게시글 좋아요 수랑 댓글 수는 또 세세한걸 보니 그냥 UI 기획상의 표현일 수도 있다ㅎ)
이처럼, 팔로워 수가 3.7억 언저리라는 것만 알면 되는 경우엔 count 결과가 꼭 정확하게 맞을 필요가 없다. 그럼 평소 CD 요청이 들어올 때는 해당 값만 잘 처리해주고, 나중에 배치 등을 활용에 싱크를 맞춰주는 방법은 어떨까?
5. Batch를 이용해 Sync 맞춰주기
우아한 형제들의 테코블에서는 이렇게 시간이 지난 후 최종적으로 데이터를 동기화해서 궁극적 일관성(Eventual Consistency)를 지키는 방법을 Sync Schedule로 표현했다. 말 그대로 데이터의 싱크를 맞춰주는 스케줄러를 의미하는 것 같다.
구현하는 방법 자체는 개인의 환경에 맞춰 생각하면 되는데, 나는 일단 Batch와 스케줄러를 이용하는 방법을 생각했다. 4번 방법을 함께 사용하고, 특정 주기마다 스케줄러를 돌면서 배치를 이용해 싱크를 맞춰주는 방식이다.
4번 방법의 문제는 사용자와 요청이 많을 때 발생하고, 사용자가 많다면 1의 자리까지 세세한 숫자는 중요도가 덜하다는 부분에서 착안하여 비실시간으로 정확한 count 개수를 업데이트 해주는 방법이다. 이렇게 하면, 4번 방법에서 예시를 들었던 이슈 (기존 코멘트 5개 있는 상황에 2명이 새로 코멘트를 남겼는데 결과가 6) 도 스케줄러에서 싱크가 맞춰지니 (댓글 수 직접 count 해서 6을 7로 업데이트 쳐준다) 문제가 해결된다.
실시간이 아니라는 점에서 기획상 문제가 될 수 있지만, 락 발생 가능을 줄이고, DB 부담을 덜어준다는 점에서 레코드 수가 아주 많을 땐 한번 쯤 고려해볼 만한 방법인 것 같다 👀
마무리
오늘은 count를 구현하는 다양한 방법에 대해 고민해보았다. 평소엔 아무 생각없이 JPARepository를 이용해 count 키워드를 남발했는데, 이번 포스팅을 위해 이것 저것 찾아보며 count도 경우에 따라 많은 고민이 필요하다는 점을 배울 수 있었다.
count 서비스의 정확한 용도, 캐시와 같은 부차적인 서비스의 도입 여부, 현재 시스템 아키텍처, 실시간성 여부 등 프로젝트의 다양한 점을 고민해보고 팀원들과 소통하며 서비스에 적합한 방법을 찾아나가는게 서버 개발자의 역할이라고 생각한다.
다음엔 count를 구현할 때 팀원들과 이 기능에서 발생할 수 있는 문제가 무엇이 있는지 한번 토론해본 후 개발에 들어가야겠다 😎
레퍼런스
- Mysql 테이블 용량 구하기 : https://ryean.tistory.com/21
[MySQL] 데이터베이스 및 테이블별 용량 (Size by databases and tables) 조회
데이터베이스별, 테이블별, 전체 용량을 아래 쿼리를 통해 확인 할 수 있다. 1. 데이터베이스별 용량 (Database Size) 조회 SELECT table_schema AS 'DatabaseName', ROUND(SUM(data_length+index_length)/1024/1024, 1) AS 'Size(MB
ryean.tistory.com
- Spring EHcache 적용하기 : https://juhi.tistory.com/66
[Spring] EHcache를 이용해 캐시 간단하게 적용하기 (feat. @ Cacheable)
자주 바뀌는 값이 아닌데, 데이터베이스에 접근해서 가져오는데 시간이 걸려서 불편할 때가 있다. 이럴 때 간단하게 서버 단에서 캐시로 들고 있을 수 있다. 필요성 데이터 중 매번 실시간 데이
juhi.tistory.com
- 트랜잭션 및 동시성 제어 : https://quantum-jumpin.tistory.com/9
[Database] 트랜잭션 및 동시성 제어
분명 동시에 같은 곳에 요청을 하는 작업이 많을 것 같은데 데이터 베이스는 이걸 어떻게 처리할까 그래서 찾아본 결과를 정리해봤다. 먼저 동시성 제어를 알려면 트랜잭션에 대해 알아야 한다
quantum-jumpin.tistory.com
- 좋아요 개수 조회 최적화하기 : https://tecoble.techcourse.co.kr/post/2022-10-10-like-count/
좋아요 개수 조회 최적화하기
속닥속닥 프로젝트(https://github.com/woowacourse-teams/2022-sokdak…
tecoble.techcourse.co.kr
'Develop > Spring' 카테고리의 다른 글
| [Spring Boot] 자바 스프링에서 처리율 제한 기능을 구현하는 4가지 방법 (2) | 2023.06.21 |
|---|---|
| [Spring Boot] Jsoup으로 OG태그 메타 데이터 크롤링하기 (1) | 2023.06.14 |
| [Spring Boot] ConstraintValidator를 이용해 나만의 validator annotation 만들기 (1) | 2023.05.15 |
| [Spring Boot] 테스트 컨테이너로 테스트하기 (3) | 2023.04.17 |
| [Spring Boot 3] SpringDoc과 Swagger를 이용해 API 문서화 자동화하기 (5) | 2023.03.21 |