

개요
즐거운 추석..에 갑자기 인덱스에 꽂혔다. 책이며 강의며 막 뒤지면서 듣는데, 이거 고냥 보고 끝낼게 아니라 정리해두면 더 기억에 잘 남겠다 싶어서 블로그도 쓱싹 쓰게 되었다 😄
쓰다보니 내용이 길어져서 이번 포스팅에선 아키텍처와 구조적 특성 위주로 작성하고, 다음 포스팅에서 인덱스와 자료구조를, 그 다음 포스팅에서 인덱스 종류에 대해서 다뤄볼까 한다. (한번 공부해서 포스팅 3개로 우려먹기 ^_____^ v)
그럼 아이엠그라운드 MySQL 아키텍처 시작!
MySQL의 아키텍처
MySQL 서버 아키텍처를 이해하면 우리가 작성한 SQL이 어떻게 실행되는지 알 수 있고, 실행 과정을 알면 튜닝 방법을 알 수 있다 🤔 우리가 아무 생각 없이 사용하는 MySQL 안에서 쿼리는 어떻게 처리되고 있을까? 한번 아키텍처를 뜯어보자.
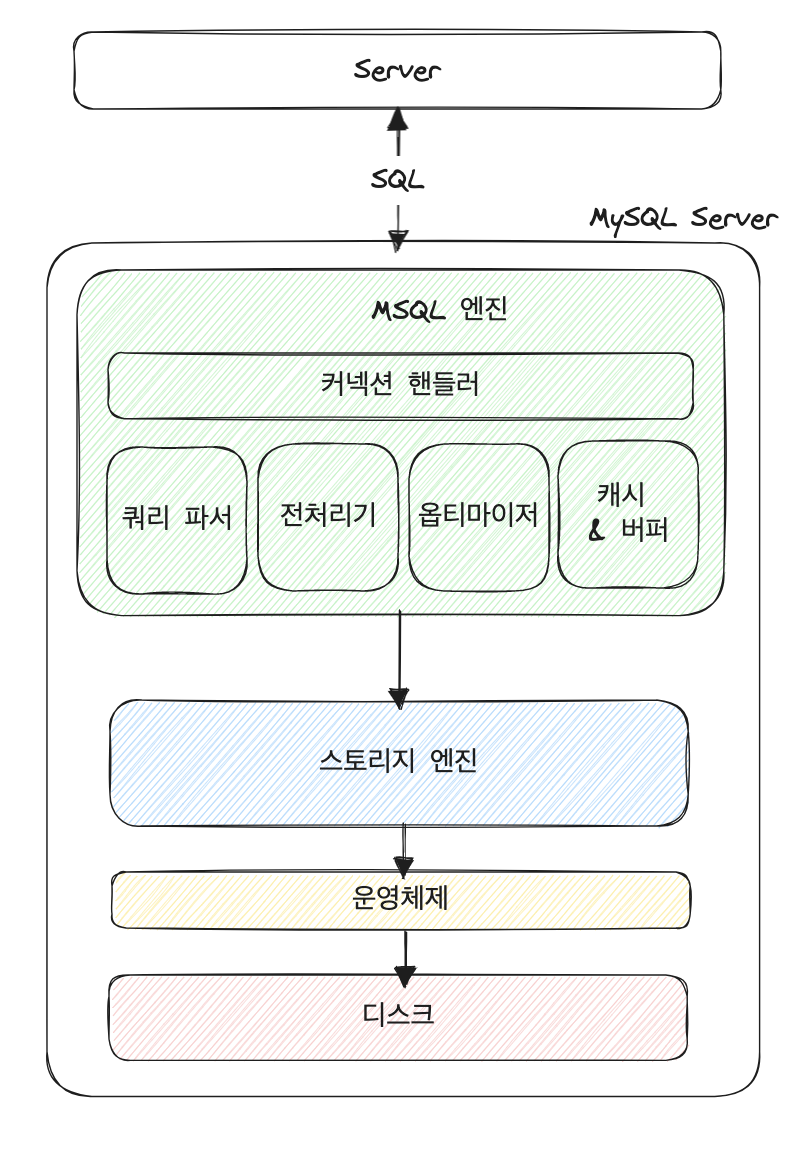
우리는 서버에서 쿼리(SQL)를 실행해 MySQL 서버에 데이터를 요구한다. 쿼리를 받는 MySQL 서버는 크게 머리 역할의 MySQL 엔진과, 손발 역할의 스토리지 엔진으로 구성된다. 각 구성 요소를 살펴보자.
1️⃣ MySQL 엔진
SQL 요청을 파싱하여 최적의 실행 계획을 수립하는 두뇌의 역할을 수행하는 친구.
SQL 요청 → 쿼리 파서 → 전처리기 → 옵티마이저 → 쿼리 실행기 순서로 실행된다.
📌 쿼리 파서
쿼리를 파싱(= MySQL이 인식할 수 있는 최소 단위의 토큰으로 분리)하여 Syntax Tree를 생성하는 친구. 이 과정에서 문법 오류를 검사하고, 기본적인 에러 메세지를 반환한다.
📌 전처리기
Syntax Tree를 이용, 쿼리 문장에서 구조적 문제점 (= 시맨틱 오류)을 검사하는 친구. 트리의 각 토큰과 실제 개체 (테이블 이름, 컬럼 이름, 내장 함수 등)를 맵핑하여 존재 여부와 접근 권한을 확인하고 걸러내어 전처리를 완료한다.
쿼리 파서와 전처리기는 프로그래밍 언어의 컴파일과 매우 유사하게 동작한다.
- 단, 서버가 동적으로 SQL을 보내므로, 프로그래밍 언어와 달리 컴파일 타임 때 검증할 수 없다..
- 따라서 매번 구문 평가를 진행한다는 점에서 컴파일과 차이를 갖는다 🙌
📌 옵티마이저
사용자의 요청으로 들어온 쿼리문을 어떻게 제일 저렴하고 제일 빠르게 처리할지 계획을 세우는 곳. 쿼리를 처리하는 여러 계획을 세우고, 각 방법의 비용과 테이블의 통계 정보를 이용해 베스트를 뽑는 방식으로 동작한다.
이때 주의할 점은 옵티마이저의 전략 결정에 따라 쿼리의 성능이 갈리며, 항상 최적의 결정을 내리는 것은 아니라는 점! 따라서 개발자는 옵티마이저가 더 나은 선택을 할 수 있도록 유도해야 한다. 보통 쿼리 힌트를 이용해 옵티마이저의 전략 결정에 끼어들 수 있다 🙄
📌 쿼리 실행기 (실행 엔진)
옵티마이저의 실행 계획을 바탕으로, Handler API를 이용해 스토리지 엔진에게 요청을 전달한다. 옵티마이저를 경영진, 실행 엔진을 PM, 핸들러를 각 업무의 실무자로 비유할 수 있다.
2️⃣ 스토리지 엔진
SQL 요청을 디스크에 전달하는 팔 다리 역할을 수행하는 친구.
- 쿼리 실행기 (실행 엔진)의 요청에 따라 데이터를 디스크에 저장하거나, 읽어온다.
- MySQL은 기본적으로 Inno DB, MyISAM 스토리지 엔진을 제공하며, 8.0 버전 기준 Inno DB를 표준으로 사용한다.
MySQL의 성능 핵심
Q. 우리는 데이터를 DB에 저장하는데, DB는 데이터를 어디에 저장하는 걸까?
A. 데이터베이스는 데이터를 보통 메모리 또는 디스크에 저장한다!
1️⃣ 메모리 vs 디스크
| 메모리 | 디스크 | |
| 속도 | 빠름 | 느림 |
| 영속성 | 전원이 공급되지 않으면 휘발 | 영속성이 있음 |
| 가격 | 비쌈 | 저렴함 |
이번 포스팅에서 우리가 알아볼 MySQL은 데이터 저장소로 디스크를 사용한다. 왜? DB가 꺼진다고 데이터가 날라가면 안되니까! 따라서 영속성을 위해서 디스크를 이용한다. (메모리 DB는 기본적으로 영속성을 보장하지 않는데, 이 때문에 Redis와 같은 몇몇 인메모리 DB는 스냅샷, 로그 등을 활용해서 영속성을 유지한다.)
여기서 문제는, 디스크의 처리 속도는 메모리에 비해 매우 느리다는 것! 그런데 왜 디스크는 속도가 느릴까? 😮
- 디스크는 외부 저장 장치이기 때문이다. 디스크에서 데이터를 읽어와 메모리에 올리고, 메모리에 올라간 데이터를 다시 읽어야 최종적으로 데이터를 사용할 수 있게 된다.
- 또, 디스크는 데이터를 페이지 단위로 읽는다. 이 과정에서 원하는 데이터를 찾을 때까지 페이지를 무한적으로 읽어야 하므로 지연이 발생한다.
따라서 데이터를 읽고 쓸 때마다 디스크에 접근해야 하는 MySQL 구조상, MySQL 성능 핵심은 디스크 I/O 접근을 최소화 하는 것이라고 이해할 수 있다.
2️⃣ 디스크 I/O를 줄이는 방법
그건 바로 메모리 활용하기!
위에서 언급했듯이, 디스크에서 읽어온 데이터는 결국 메모리에 올라간다. 따라서 메모리에 이미 필요한 데이터가 올라와 있다면, 굳이 디스크에 다시 접근할 필요가 없다. 🤔 따라서 데이터를 읽을 때, 또는 데이터를 쓸 때 메모리를 최대한 활용하여 디스크 접근을 줄일 수 있다. 각 동작에서 메모리를 활용하는 방법은 다음과 같다.
| 종류 | 방법 |
| read | 메모리에 올라온 데이터를 이용해 요청을 처리한다. 즉, 캐시 히트율을 높이는 방식! |
| write | 메모리에 데이터를 쓰고, 이후 한꺼번에 디스크로 보낼 수 있다. WAL을 이용하는 방식. |
read는 그냥 우리가 알고 있는 캐싱 방법을 이용하는 친구다. 하지만 write에서 이용하는 WAL은 조금 생소한 친구다. 알아보자.
3️⃣ WAL (Write Ahead Logging) 이란?
디스크 접근 방식은 두 가지가 있다.

- 랜덤 I/O : 디스크에서 무작위로 데이터를 가져오는 방식
- 순차 I/O : 디스크에서 연속된 블록의 데이터를 가져오는 방식
디스크는 페이지 단위로 데이터를 읽기 때문에, 당연히 순차 I/O의 성능이 좋다. 이를 이용해 write 작업을 할 때 일부러 작업을 지연시켜 순차 I/O를 사용하는 식으로 성능을 개선할 수 있다!
방법은 다음과 같다.
- write 요청이 들어오면, 이를 메모리에 쌓는다.
- 요청이 적정 사이즈 이상 쌓이면, 메모리에 담긴 write 연산을 한 번에 디스크로 보낸다.
한꺼번에 요청을 보내기 때문에 디스크 접근 횟수가 줄어들며, 동시에 끝에서부터 순차적으로 데이터를 저장할 수 있기 때문에 성능이 향상된다. 하지만 이 방법에는 문제가 있는데, 바로 메모리를 사용한다는 점이다. 메모리 특성상, 디스크에 작업이 반영되기 전 요청들이 휘발될 수 있다는 위험이 존재하기 때문이다 👀
이때 메모리에 쌓인 연산의 휘발을 방지하기 위해 사용하는 것이 WAL이다. WAL을 활용하는 DBMS에서 모든 연산들은 디스크에 적용되기 전 로그로 기록된다. 이를 이용해 위 과정을 다음과 같이 개선할 수 있다.
- 트랜잭션이 발생하면 로그에 기입한다.
- write 요청이 들어오면 메모리에 쌓는다.
- 요청이 디스크에 반영되기 전, 예기치 못한 이슈로 메모리가 휘발된다.
- 메모리 대신 로그를 flush 하여 디스크에 일괄 write 한다.
처음부터 인메모리 DB나 캐시를 쓰면 안될까?
된다! 하지만 한계가 있다.
1️⃣ 인메모리 DB를 메인 DB로 쓸 때의 한계
일단 메모리, 즉 RAM은 공간이 한정되어 있어 대량의 데이터를 저장하기 어렵다. 만약 메모리 용량이 부족할 경우, 디스크 용량을 끌어다 쓰는 메모리 스왑이 발생하고, 여기서 디스크 I/O가 다시 발생한다. 그렇다고 용량이 큰 RAM을 사용하자니 가격이.. 😇 상대적으로 디스크가 한참 저렴하다. (ex. 다나와 기준, 32GM RAM은 124,250원, 1TB SSD는 57,000원.)
또 데이터베이스는 백업과 복원이 필수적이기에, 영속성이 꼭 필요하다. 자주 쓰이는 인메모리 DB인 Redis의 경우, 스냅샷과 AOF를 제공해 영속성을 지원한다. 하지만 이는 결국 스냅샷과 로그를 디스크에 저장하는 방식으로 구현된다. Redis를 사용하더라도 결국 디스크를 사용하는 구조가 되는 것..! 🤔
2️⃣ 모든 데이터를 캐싱할 때 생기는 문제
그럼 디스크에 데이터를 저장하고, read 작업에 필요한 데이터만 캐싱하는 건 어떨까? 안타깝지만 이 친구도 문제가 있다.
일단 과도한 비용이 소모된다. 캐시는 메모리를 사용한다. 따라서 빠른 응답을 위해 모든 데이터를 메모리에 올린다면, 앞서 언급한 메모리 스왑 등 너무 많은 비용 (= 컴퓨팅 리소스)가 필요하다.
또 데이터 무결성 유지가 어렵다는 문제도 있다. 오래 전에 캐시되어 최신 데이터와 싱크가 맞지 않는다면, 사용자에게 잘못된 데이터가 노출될 수 있다. 따라서 캐시는 항상 만료 정책을 적절히 책정해야 한다. 만약 모든 데이터를 캐시했다면 만료 정책을 정하기 어려울 것이며, 또한 데이터를 업데이트 할 때마다 캐시를 업데이트 해야 하므로 불필요한 프로세스가 발생한다. 따라서 무결성 유지를 지키기 위해 불필요한 부하가 발생하는 문제가 있다 🔨
따라서, 인메모리 DB를 메인 DB로 사용하는 것은 충분한 PoC를 거치며 고민해야 하는 주제다.
동시에 캐시는 자주 접근되며 변경이 잦지 않은 데이터에 적절히 사용하도록 설계해야 한다.
마무리
오늘은 이렇게 MySQL 서버 아키텍처와 구조적 특성에 대해 알아봤다. WAL은 이번에 처음 알게되었는데, 역시 세상엔 흥미로운 기술이 많다 🤩 이번 포스팅을 쓰면서 이런저런 레퍼런스를 찾아보다가 캐시는 실버 불렛이 될 순 없다는 말을 봤는데, 그게 특히 인상 깊게 남는다. 트레이드 오프는 (적어도 개발에서는) 진리라고 생각한다... 🤔
다음 포스팅에선 캐시를 쓰지 않고도 read 성능을 개선할 수 있는 방법, 인덱스에 대해 알아봐야겠다 ✨
레퍼런스
WAL (Write-Ahead-Logging)
[DB에 저장되는 데이터는 어디에 저장될까?] 하드디스크에 저장된다. 하드디스크에 저장된 데이터를 읽어 우리가 볼 수 있도록 데이터를 가져다 준다. 이 디스크를 읽는 두 가지 방식 (1) Sequential
nays111.tistory.com
- Real MySQL 8.0 : https://www.yes24.com/Product/Goods/103415627
Real MySQL 8.0 (1권) - 예스24
『Real MySQL 8.0』은 『Real MySQL』을 정제해서 꼭 필요한 내용으로 압축하고, MySQL 8.0의 GTID와 InnoDB 클러스터 기능들과 소프트웨어 업계 트렌드를 반영한 GIS 및 전문 검색 등의 확장 기능들을 추가로
www.yes24.com
'Develop > Database' 카테고리의 다른 글
| [MySQL] MySQL의 인덱스 탐구하기 1 (feat. B-Tree) (1) | 2023.10.14 |
|---|---|
| [MySQL] 트랜잭션, ACID와 MySQL이 트랜잭션의 ACID를 보장하는 방법들 (0) | 2023.10.08 |